AWS Data Engineering Training In Hyderabad
with
100% Placements & Internships
- Comprehensive Curriculum
- Expert Trainers
- Real-Time Projects
- Certification
Table of Contents
ToggleAWS Data Engineering Course In Hyderabad
Batch Details
| Trainer Name | Mr. Dinesh |
| Trainer Experience | 10+Years |
| Timings | Monday to Friday (Morning and evening) |
| Next Batch Date | 06-AUG-2025 AT 11:00 AM |
| Training Modes | Classroom & Online |
| Call us at | +91 9000360654 |
| Email us at | awsmasters.in@gmail.com |
| For More Details at | For More Demo Details |
AWS Data Engineering Institute In Hyderabad
Why choose us?
- Expert-led AWS Data Engineering training
- Big Data & Cloud professional mentorship
- Real-time pipeline & cloud integration projects
- Tools covered: Glue, Redshift, EMR, Athena
- Capstone projects with data lakes & warehousing
- Job-role-based curriculum (Data Engineer, ETL, Cloud)
- Structured & unstructured data hands-on practice
- Real-time streaming with Kafka & Kinesis
- Advanced SQL, Python, and PySpark modules
- Resume building & LinkedIn optimization
- Interview-focused task preparation
- Complete post-training career support
AWS Data Engineering In Hyderabad
Curriculum
Module 1 - Introduction to Data Engineering
- What is Data Engineering?
- Role in the Data Lifecycle
- Key skills and tools used
Module 2 - Cloud Computing Fundamentals
- IaaS, PaaS, SaaS models
- Benefits of cloud over on-prem
- Public vs Private vs Hybrid cloud
Module 3 - AWS Fundamentals
- AWS global infrastructure
- Regions, Availability Zones
- AWS Free Tier, Console walkthrough
Module 4 - Introduction to S3 (Simple Storage Service)
- Buckets, Objects, Folder structures
- Versioning, Lifecycle rules
- Static website hosting in S3
Module 5 - S3 Advanced Features
- Storage classes (Standard, IA, Glacier)
- Encryption (SSE-S3, SSE-KMS)
- Data transfer and pricing concepts
Module 6 - Introduction to IAM (Identity & Access Management)
- Users, Groups, Roles, Policies
- Policy structure and permissions
- IAM best practices
Module 7 - EC2 for Data Engineering
- EC2 instance types and pricing
- Launching, connecting, and using EC2
- Security groups, AMIs, and key pairs
Module 8 - VPC and Networking Essentials
- What is a VPC?
- Subnets, routing tables, gateways
- Security groups vs NACLs
Module 9 - AWS CLI & SDKs
- AWS CLI setup and configuration
- Common CLI commands for S3, EC2
- Introduction to Boto3 (Python SDK)
Module 10 - Understanding Data Formats
- CSV, TSV, JSON, XML, Parquet, ORC
- Row-based vs Column-based formats
- Compression techniques (GZIP, Snappy)
Module 11 - AWS Glue Introduction
- What is AWS Glue?
- Components: Crawlers, Catalog, Jobs
- Use cases in data pipelines
Module 12 - Glue Crawlers & Data Catalog
- Creating and configuring crawlers
- Understanding metadata and schemas
- Integrating with S3 and Redshift
Module 13 - AWS Glue Jobs & PySpark
- Writing Glue ETL Jobs with PySpark
- DynamicFrames vs DataFrames
- Reading/Writing to S3
Module 14 - Glue Job Triggers & Scheduling
- Event-based vs time-based triggers
- Automating workflows
- Glue Workflows overview
Module 15 - Glue Job Bookmarking & Partitions
- Incremental loading strategies
- Managing state with bookmarks
- Handling S3 partitions in Glue
Module 16 - Amazon Redshift Overview
- Redshift architecture & components
- Clusters, nodes, and snapshots
- Redshift Spectrum introduction
Module 17 - Loading Data into Redshift
- COPY command and manifest files
- Using S3 as data source
- Best practices for performance
Module 18 - Querying & Optimizing Redshift
- SQL queries in Redshift
- Distribution styles and sort keys
- Vacuuming, analyzing tables
Module 19 - Amazon Athena Basics
- Serverless SQL querying on S3
- Integration with Glue Catalog
- Creating databases and tables
Module 20 - Amazon Athena Advanced Use
- Partitioning and performance tuning
- Working with Parquet and ORC
- Using CTAS and views
Module 21 - Amazon EMR for Big Data
- Introduction to EMR and Hadoop
- Launching and configuring clusters
- Integrating with Spark, Hive, Presto
Module 22 - Spark on EMR
- Introduction to EMR and Hadoop
- Launching and configuring clusters
- Integrating with Spark, Hive, Presto
Module 24 - Real-Time Data with Amazon Kinesis
- Kinesis Data Streams & Firehose
- Kinesis Analytics basics
- Real-time processing pipeline design
Module 25 - Lambda Functions for Data Engineering
- Creating Lambda functions
- Event triggers (S3, Glue, CloudWatch)
- Serverless transformation logic
Module 25 - Orchestration with AWS Step Functions
- Workflow creation using Step Functions
- Integrating Glue, Lambda, and more
- Error handling and retries
Module 26 - Data Lake Design on AWS
- Raw, Processed, Curated layers
- Cataloging and indexing strategy
- Choosing storage formats
Module 27 - Glue Studio Visual Job Design
- GUI-based job creation
- Adding sources, targets, and transforms
- Script generation and editing
Module 28 - Data Pipeline Design Principles
- Ingestion, storage, transformation, delivery
- Batch vs real-time pipelines
- Decoupled, modular architecture
Module 29 - CloudWatch Monitoring for Data Jobs
- Logs, Metrics, and Dashboards
- Alert creation and notifications
- Troubleshooting ETL jobs
Module 30 - Handling Schema Evolution
- Managing schema changes in Glue
- Partition projection techniques
- Compatibility strategies
Module 31 - Data Quality & Validation
- Checking nulls, duplicates, ranges
- Row count validations
- Logging validation failures
Module 32 - Error Handling in Pipelines
- Try-catch blocks in PySpark
- Logging errors and sending alerts
- Dead-letter queue (DLQ) concept
Module 33 - Encryption & Data Security
- KMS overview and key management
- Encrypting S3, Redshift, and Glue data
- Access control with IAM
Module 34 - Data Governance with Lake Formation
- What is Lake Formation?
- Managing access centrally
- Tag-based and column-level access
Module 35 - Version Control with Git & CodeCommit
- Git basics and repo setup
- Storing and managing Glue scripts
- CI/CD intro for data pipelines
Module 36 - Introduction to AWS CDK for Data Infra
- Infrastructure as code (IaC)
- Deploying Glue, S3, IAM via CDK
- CDK vs CloudFormation
Module 37 - AWS Cost Optimization for Data Workloads
- Glue pricing models
- Spot vs on-demand for EMR
- Storage cost control in S3
Module 38 - Redshift vs Snowflake Comparison
- Architecture and performance
- Use cases and pricing
- Integration with AWS stack
Module 39 - Integrating with 3rd Party Tools
- Connecting Tableau, Power BI to Redshift
- API-based ingestion with Lambda
- Using Airflow with AWS
Module 40 - Data Archiving & Retention
- Cold storage in Glacier
- Data lifecycle policies in S3
- Retention rules in Glue and Redshift
Module 41 - Streaming Ingestion with Firehose
- Kinesis Firehose architecture
- Transform with Lambda
- Destination: S3, Redshift, Elasticsearch
Module 42- Data Catalog Best Practices
- Table naming conventions
- Partition management
- Tagging and lineage
Module 43 - Data Migration with AWS DMS
- Source to AWS migration
- Database compatibility
- Monitoring DMS tasks
Module 44 - Redshift Performance Tuning
- Query plan analysis
- Workload management (WLM)
- Query monitoring rules (QMR)
Module 45 - AWS Data Engineering Capstone Project
- Designing full ETL pipelines
- Real client scenario implementation
- Presentation and documentation
Module 46 - AWS Data Engineer Associate
- Certification overview
- Domain-wise practice
- Time-based mock exam
Module 47 - Resume Building Workshop
- Role-based resume templates
- Highlighting cloud and ETL projects
- LinkedIn optimization
Module 48 - Interview Preparation & Mock Rounds
- 20+ technical interview questions
- HR and scenario-based mock rounds
- Feedback and improvement plan
Module 49 - Final Project Review & Feedback
- Trainer assessment of Capstone
- Peer review and suggestions
- Corrections and project polish
Module 50 - Career Guidance & Placement Support
- Trainer assessment of Capstone
- Peer review and suggestions
- Corrections and project polish
AWS Data Engineering Trainer Details
INSTRUCTOR
Mr. Dinesh
Expert & Lead Instructor
10+ Years Experience
About the tutor:
Mr. Dinesh, our AWS Data Engineering Trainer, brings over 10+ years of industry experience in cloud computing, big data, and IT infrastructure. With deep expertise in Amazon Web Services (AWS), he has delivered end-to-end data solutions for top MNCs and emerging startups across domains like finance, healthcare, and retail.
He specializes in teaching key AWS data services such as AWS Glue, Redshift, S3, Athena, EMR, Kinesis, and Lambda, with real-time implementation using ETL pipelines, PySpark, and data lake architectures. His training style emphasizes hands-on labs, real-time projects, and production-grade pipeline building, ensuring learners gain practical experience that aligns with industry expectations.
In addition to technical skills, Mr. Dinesh guides students on resume building, AWS Data Engineering certification preparation, mock interviews, and career mentorship. His goal is to make every learner job-ready and confident, helping them succeed in high-demand roles such as Cloud Data Engineer, Big Data Engineer, and ETL Developer on AWS.

Why Join Our AWS Data Engineering Institute In Hyderabad
Key Points
- Learn from Experts
Our trainers have 10+ years of real experience in AWS and Data Engineering.
They teach with real-world examples and guide you personally.
You’ll understand everything clearly, even if you’re new to it.
- Work on Real Projects
You’ll build real AWS projects using tools like S3, Glue, and Redshift.
This helps you understand how things work in real companies.
You can also show these projects in your resume.
- Job-Focused Course
Our course covers all the topics needed for a data engineering job.
You’ll learn about ETL, data pipelines, and cloud tools step by step.
We teach what companies are actually looking for.
- Placement Support
We help you with resumes, interview practice, and job updates.
Our team will guide you until you get placed.
Many of our students are now working in top MNCs.
- Get AWS Certified
We train you to clear the AWS Data Engineer certification exam.
You’ll get notes, mock tests, and expert tips.
This certificate adds great value to your profile.
- Flexible Classes
Attend classes online or offline, whichever suits you.
We have weekend and weekday batches available.
You’ll also get recordings to revise anytime.
- Affordable Fees
Our training is high-quality but budget-friendly.
You can also pay in easy EMI options.
Great value for your career investment.
- Practice on Live AWS Console
You will work directly on the real AWS platform, not just theory.
You’ll learn how to use tools and handle errors like in real jobs.
It’s the best way to get confident with AWS.
- Trusted Institute in Hyderabad
We have trained and placed hundreds of students successfully.
Our reviews speak for our quality and results.
You’ll be in safe hands to start your cloud career.
What is AWS Data Engineering?
- AWS Data Engineering is the process of collecting, storing, processing, and moving data using Amazon Web Services. It helps businesses manage large amounts of data in the cloud. Engineers use AWS tools to build smart data systems for analysis and decision-making.
- AWS supports both real-time data (live updates) and batch data (scheduled jobs). This is useful for businesses that need quick reports or large data processing overnight. Engineers choose the best method depending on the use case.
- AWS offers powerful services like S3, Glue, Redshift, and EMR to work with big data. These tools help you clean, transform, and prepare data for reporting. Even very large datasets can be managed easily and quickly.
- AWS ensures your data is safe with strong security and access controls. It also grows with your needs, whether you have 1 GB or 1 TB of data. You don’t need to manage physical servers — AWS handles it all.
- Data engineers create pipelines that move data from one place to another. They automate the flow of data from sources to storage to analytics tools. This makes the entire data process fast, reliable, and repeatable.
- AWS Data Engineering is a high-demand skill in today’s job market. Companies need skilled engineers to manage and understand their data. It’s a great career path with good salary and growth opportunities.
Objectives of the AWS Data Engineering In Hyderabad
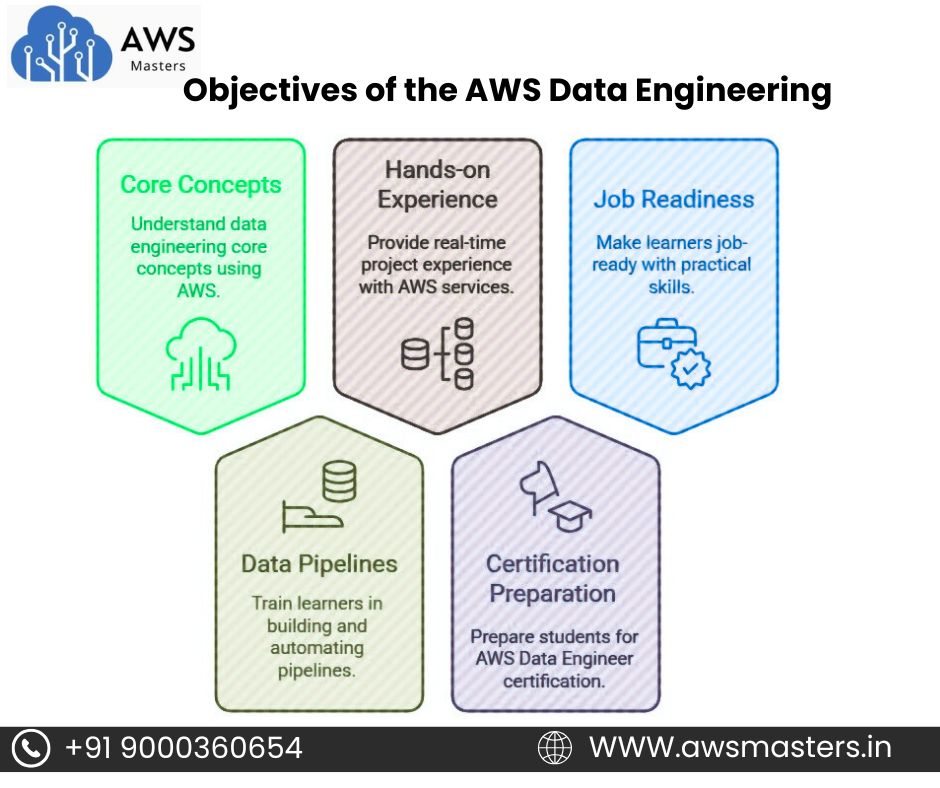
- To help students understand core concepts of data engineering using AWS tools and services.
- To train learners in building, managing, and automating data pipelines in the cloud.
- To provide hands-on experience with real-time projects using AWS services like Glue, Redshift, S3, and EMR.
- To prepare students for AWS Data Engineer certification and real-world job roles.
- To make learners job-ready with practical skills, project exposure, and placement support.
Prerequisites of AWS Data Engineering
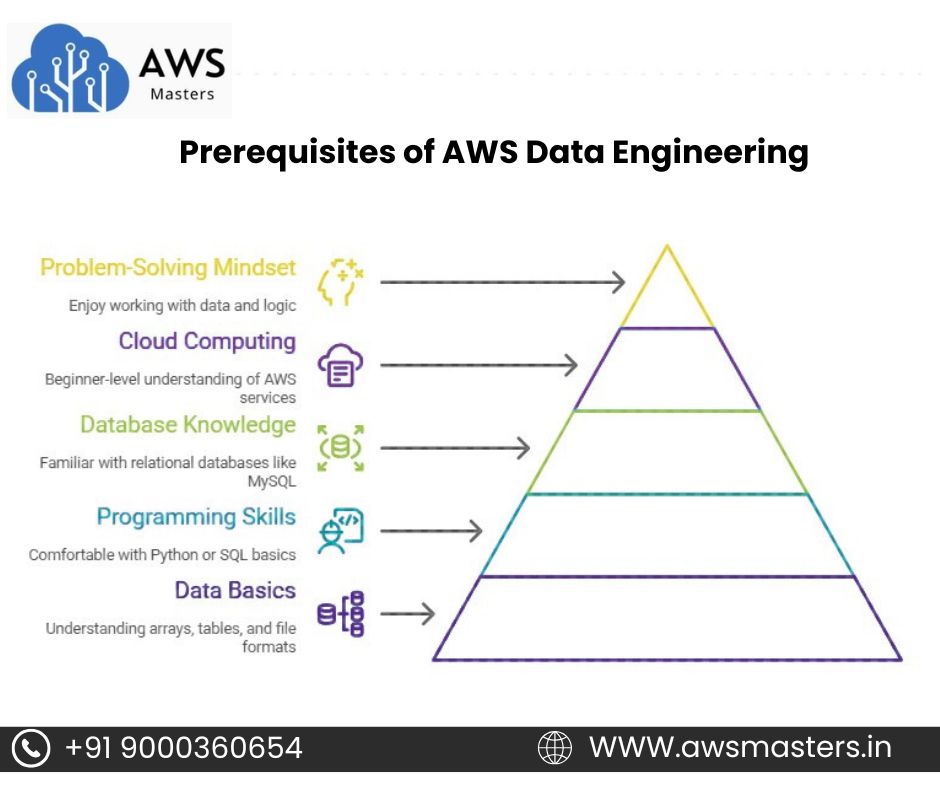
- Understanding of Python or SQL helps in writing data transformation logic. You don’t need to be an expert, just comfortable with basics.
- Knowing how relational databases like MySQL or PostgreSQL work is useful. Helps in understanding data storage and querying.
- Basic idea of arrays, tables, and file formats like CSV or JSON is helpful. Used in handling data during processing.
- A beginner-level understanding of cloud computing or AWS is a plus. It makes it easier to learn services like S3, EC2, and IAM.
- You should enjoy working with data, logic, and problem-solving. This mindset makes learning data engineering smoother and more fun.
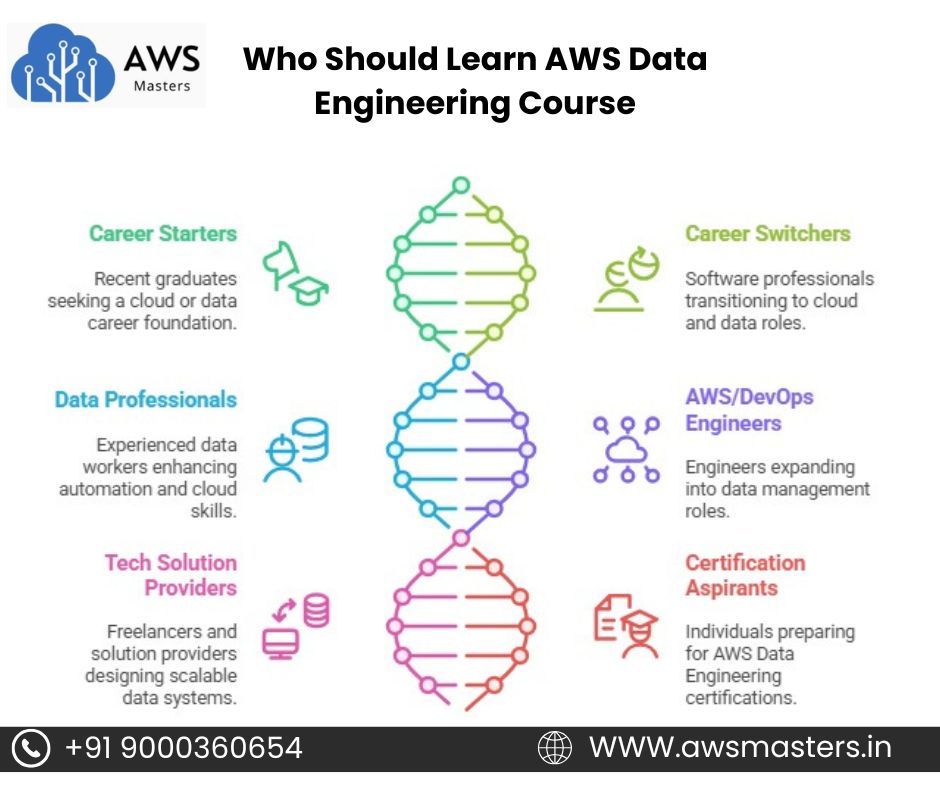
Who should Learn AWS Data Engineering course
- If you're a recent graduate looking to start a career in cloud or data, this course is perfect. It builds a strong foundation in AWS and data handling skills.
- Software developers, testers, or support engineers wanting to switch to cloud and data roles. It helps you upskill and move into high-demand data engineering jobs.
- If you're already working with data and want to go deeper into automation and cloud pipelines. AWS Data Engineering adds strong technical value to your profile.
- Engineers familiar with AWS or DevOps can expand their role into data management. Learning data engineering complements your existing cloud skills.
- Those offering tech solutions or freelancing in cloud or analytics can benefit greatly. You’ll learn how to design scalable and automated data systems.
- If you're preparing for AWS Data Engineering or Big Data certifications. This training will guide you with hands-on practice and exam readiness.
Data Engineering Training in Hyderabad
Course Outline
Understand the basics of cloud computing and why AWS is the most popular cloud platform. Learn about core AWS services and how data engineering fits into the cloud ecosystem. This sets the foundation for the rest of the course.
Learn how to store, manage, and access data using Amazon S3. Understand buckets, file formats (CSV, JSON, Parquet), and permission settings. S3 is the base storage layer for most AWS data workflows.
Master AWS Glue to automate Extract, Transform, Load (ETL) jobs. Use Glue Studio and PySpark to process raw data into useful formats. Helps in cleaning and preparing data for analytics.
Set up and work with Redshift for large-scale data storage and analytics. Perform fast queries using SQL and manage tables in a cloud warehouse. Learn how to optimize performance and cost.
Use Athena to run SQL queries directly on data stored in S3. No need to move data into databases — fast and serverless. Perfect for quick, cost-effective analysis.
Learn how to use AWS Lambda for serverless data processing. Trigger automated functions using S3 or Glue events. No need to manage infrastructure.
Work with tools like Apache Spark and Hadoop using Amazon EMR. Process large datasets efficiently using distributed computing. Ideal for big data and machine learning workflows.
Design and build end-to-end data pipelines using multiple AWS services. Move data from source to storage to analytics automatically. Includes real-world scenarios and hands-on practice.
Secure your pipelines using IAM roles, encryption, and data protection techniques. Use AWS CloudWatch to monitor, debug, and optimize your workflows. Learn best practices used by top cloud professionals.
AWS Data Engineering In Hyderabad
Modes
Classroom Training
- Daily Recorded Videos
- One - One Project Guidence
- Practical Application
- Get support till you are placed
- Mock Interviews
- Well-Organized Syllabus
Online Training
- Flexible Learning Schedule
- Recorded Video access
- Whatsapp Group Access
- Doubt Clearing Sessions
- Daily Session Recordings
- Real-world Projects
Corporate Training
- Live Project Training
- On-site or Virtual Training Sessions
- Doubt Clearing Sessions
- Daily Class Recordings
- Team-building Activities
- Video Material Access
AWS Data Engineering Training In Hyderabad
Career Opportunities
01
High Demand in IT Industry
AWS Data Engineers are in great demand across IT companies, MNCs, and startups.
With most businesses moving to the cloud, skilled professionals are needed to manage data.
You’ll be entering a fast-growing and future-proof career.
02
Roles You Can Apply For
After completing this training, you can apply for roles like AWS Data Engineer, Cloud Data Engineer, ETL Developer, or Big Data Engineer.
These roles focus on data processing, storage, and automation on AWS.
You’ll also be prepared for DevOps + Data roles in some companies.
03
Attractive Salary Packages
AWS Data Engineers earn high salaries due to their niche skills
Even entry-level positions offer good pay, and experienced professionals can earn 10+ LPA or more.
04
Opportunities Across Domains
Data engineers are needed in banking, healthcare, e-commerce, fintech, and more
Your skills are not limited to tech companies — every industry needs data management.
This opens up a wide range of job options.
05
Freelance and Remote Jobs
With AWS being cloud-based, many companies hire remote or freelance data engineers.
You can work from anywhere while handling global data projects.
Perfect for those looking for flexible career options.
06
Strong Growth Path
Start as a data engineer and grow into roles like Data Architect, Cloud Solution Architect, or Analytics Lead.
The more projects and certifications you add, the faster you grow.
It’s a rewarding long-term career path with leadership opportunities.
AWS Engineering Institute In Hyderabad
Skills Developed
Cloud Platform Expertise
You’ll gain hands-on experience with AWS core services like S3, EC2, IAM, and CloudWatch.
This helps you understand how cloud infrastructure works in real-time.
You’ll also learn how to deploy and manage data systems in AWS.
ETL and Data Pipeline Skills
Learn how to build ETL (Extract, Transform, Load) processes using AWS Glue and PySpark.
Understand how to automate data movement from source to destination.
This is a key skill for any data engineering role.
Big Data Handling
Work with large datasets using tools like Amazon EMR, Spark, and Hadoop.
You’ll learn how to process, clean, and manage big data efficiently.
This skill is in high demand for modern analytics and AI applications.
Data Warehousing & SQL
Master data warehousing concepts using Amazon Redshift.
Write complex SQL queries to analyze structured data.
You’ll understand how to design and optimize data models.
Serverless Computing & Automation
Get trained in AWS Lambda to create serverless data workflows.
Automate repetitive data tasks without managing infrastructure.
It helps you build scalable and cost-effective solutions.
Security, Monitoring & Best Practices
Learn how to secure data pipelines using IAM roles, encryption, and access policies.
Use CloudWatch and AWS logs to monitor and troubleshoot jobs.
You’ll follow industry best practices for performance and security.
AWS Data Engineering Course Online
Certifications

- This is the main certification for cloud data engineers by AWS. Our course helps you prepare fully with hands-on projects and mock tests.
- Also useful for understanding AWS architecture and core services. It adds more value if you're aiming for broader cloud roles.
- Certified trainers guide you with preparation tips, practice questions, and real scenarios. You'll know how to register, prepare, and pass the exam confidently.
- We provide sample questions, exam tips, and mock tests to boost your confidence. You’ll be ready to face the actual certification exam.
- AWS certifications are globally recognized and help you stand out. They improve your job chances, salary, and credibility in the cloud industry.
Companies that Hire From Amazon Masters












AWS Data Engineering Course In Hyderabad
Benefits
- Hands-On Practical Training
You’ll work directly on real AWS tools like S3, Glue, and Redshift.
Practical labs and projects help you gain real-world experience.
This makes you confident and job-ready from day one.
- Expert Trainers with Real Experience
Learn from AWS-certified professionals who’ve handled live cloud projects.
They share industry insights and guide you with real case studies.
You get more than theory—you learn how it’s done in companies.
- Job-Oriented Curriculum
The course is designed as per the latest industry requirements.
You’ll learn how to build end-to-end data pipelines, automate ETL, and manage big data.
Everything taught is focused on what companies actually need.
- Placement Assistance
We support you with resume preparation, mock interviews, and job referrals.
Our placement team works with top companies and startups.
You’ll get full support until you land your first data engineering role.
- Certification Preparation
This training helps you crack AWS certifications like Data Engineer Associate.
You’ll get mock tests, practice questions, and trainer guidance.
Certified professionals get better job roles and higher salaries.
- Flexible Learning Options
Choose from online or classroom training based on your comfort.
Weekend, weekday, and fast-track batches available.
You’ll also get lifetime access to recordings and materials.
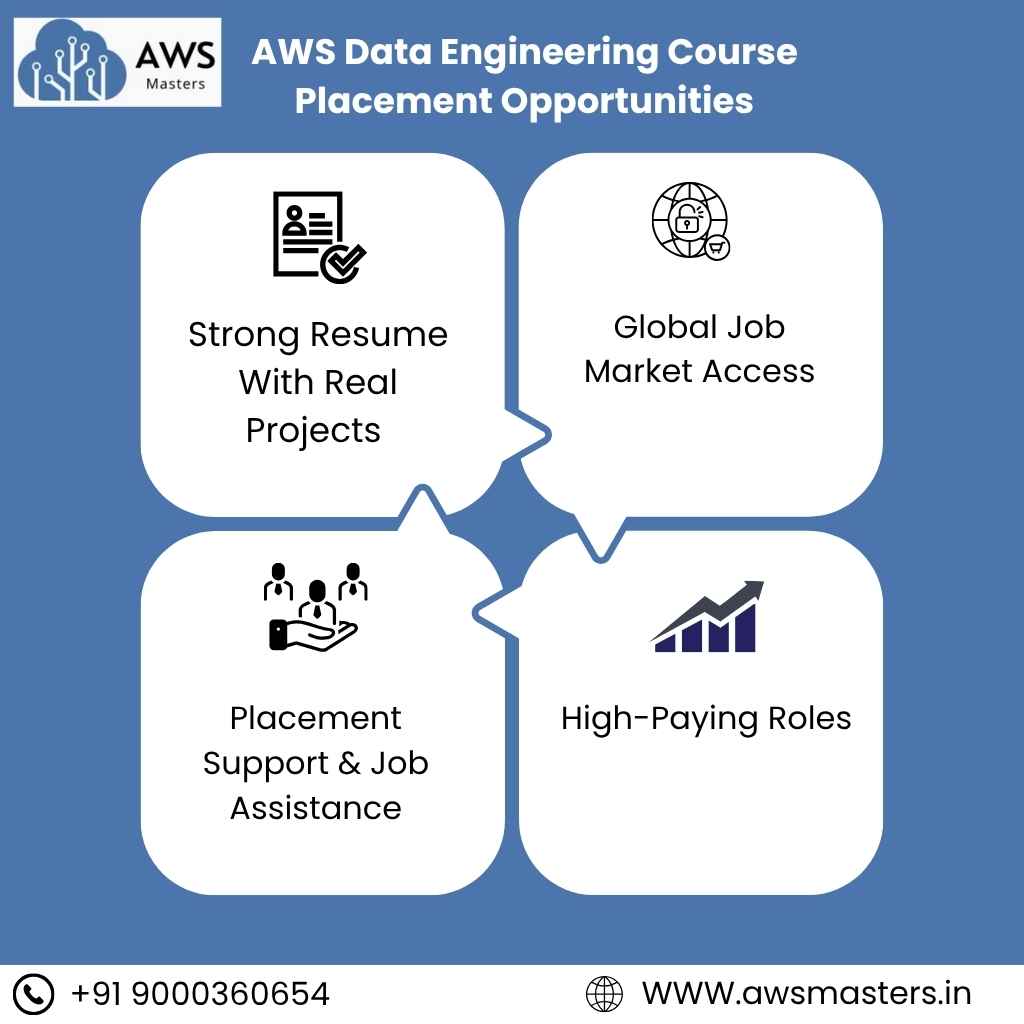
AWS Data Engineering Course
Placement Opportunities
- High Demand for AWS Data Engineers
- Roles OF high-paying and growth-oriented
- Global Job Market Access
- Strong Resume with Real Projects
- Placement Support & Job Assistance
AWS Data Engineering
Market Trend
Cloud Adoption is Booming
Companies of all sizes are rapidly moving to cloud platforms like AWS. This shift is driving massive demand for cloud and data engineering skills. AWS remains the global leader in cloud services.
Rise of Data-Driven Decisions
Every business today relies on data to make smarter decisions This creates the need for skilled data engineers who can process and manage large datasets on AWS The trend is growing across all industries.
High Demand for AWS Data Engineers
Job portals show a sharp rise in openings for AWS Data Engineers Companies are hiring professionals who can build scalable data pipelines in the cloud. This role is now among the most in-demand in tech.
Big Data Meets Cloud
With the explosion of big data, cloud platforms like AWS are key to managing it efficiently.
Data engineering combines cloud tools and big data technologies like Spark and Hadoop.This powerful combo is shaping the future of tech jobs.
Remote Work & Global Hiring
Cloud-based roles, including data engineering, support remote and hybrid work. Companies now hire talent globally, not just locally. This opens up more job opportunities for trained professionals.
Certification Value is Rising
AWS certifications like Data Engineer Associate are gaining global recognition.Certified professionals are getting faster interviews and better salaries. Training aligned with certifications adds strong market value.
Career Switch Opportunities
Many professionals from software testing, support, and BI are switching to AWS Data roles. It’s seen as a future-proof career with good growth and job security.Training makes the switch smoother and more confident.
Hyderabad as a Tech Hub
Hyderabad is growing as a major IT and cloud technology hub. Many AWS partner companies and MNCs are hiring locally.Training in Hyderabad offers strong job connections and local support.
FAQs
1. What is AWS Data Engineering?
It is the process of collecting, storing, processing, and analyzing data using AWS cloud tools and services.
2. Who should learn AWS Data Engineering?
Freshers, IT professionals, data analysts, and anyone interested in cloud and big data roles.
3. Is prior experience required to join the course?
No, basic knowledge of programming and databases is helpful but not mandatory.
4. What is the duration of the course?
Typically 2 to 3 months, depending on batch type (weekday/weekend).
5. Is the training available online?
Yes, we offer both online and offline (Hyderabad) training modes.
6. Do you provide recorded sessions?
Yes, lifetime access to session recordings is provided.
7. Can I attend a demo class before joining?
Absolutely! We offer free demo sessions to help you decide.
8. Do you provide course completion certificates?
Yes, you’ll receive a certificate after successfully completing the course.
9. Is this course beginner-friendly?
Yes, it’s designed for beginners as well as professionals with some tech background.
10. What’s the difference between AWS and AWS Data Engineering?
AWS is the platform; Data Engineering focuses on handling data using AWS tools like Glue, S3, and Redshift.
11. Which AWS tools will I learn?
S3, Glue, Redshift, Lambda, Athena, EMR, CloudWatch, and more.
12. Will I learn how to build data pipelines?
Yes, building and automating data pipelines is a core part of the course.
13. Do you cover ETL concepts?
Yes, using AWS Glue and PySpark, we cover real-time ETL workflows.
14. Will I learn Big Data tools?
Yes, using AWS Glue and PySpark, we cover real-time ETL workflows.
15. Are real-time projects included in the training?
Yes, hands-on projects using real data are part of the training.
16. Will I learn data warehousing?
Yes, you’ll work with Amazon Redshift for warehousing and analytics.
17. Do you teach SQL and Python?
Basic SQL and Python needed for data transformation are included.
18. Is PySpark taught in this course?
Yes, PySpark is covered especially with AWS Glue.
19. Will I learn how to secure data on AWS?
Yes, topics like IAM roles, encryption, and data protection are covered.
20. Do you teach both batch and real-time processing?
Yes, including scheduled jobs and event-driven pipelines.
21. Which certification does this course prepare me for?
Mainly AWS Certified Data Engineer – Associate (new), and optionally Solutions Architect – Associate.
22. Is certification included in the course fee?
No, certification exam fees are separate and paid to AWS directly.
23. Do you provide mock exams and practice questions?
No, certification exam fees are separate and paid to AWS directly.
24. How hard is the AWS Data Engineer certification?
With the right training and practice, it’s manageable even for beginners.
25. Can I attempt the exam after this course?
Yes, you will be fully prepared to attempt the exam after completing the training.
26. What job roles can I apply for after the course?
AWS Data Engineer, Big Data Engineer, Cloud ETL Developer, Data Analyst (Cloud), etc.
27. Do you provide placement assistance?
Yes, including resume help, mock interviews, and job referrals.
28. Is there real demand for AWS Data Engineers?
Yes, companies across all domains are hiring cloud data engineers.
29. What is the average salary for AWS Data Engineers?
In India, entry-level salaries range from ₹5–8 LPA; experienced roles can go up to ₹20+ LPA.
30. Which companies hire AWS Data Engineers?
TCS, Accenture, Cognizant, Infosys, Amazon, startups, and global MNCs.
31. Do I need a high-end laptop?
Any system with internet and 8GB RAM is sufficient. AWS Cloud handles most processing.
32. Is AWS free to use for practice?
AWS offers a Free Tier. We guide you on how to use it safely during training.
33. Do you help set up AWS accounts?
Yes, we assist you in creating and configuring your AWS Free Tier account.
34. Will I get lifetime access to materials?
Yes, all study materials, notes, and recordings are available for lifetime access.
35. Can I ask doubts after class hours?
Yes, you can reach out via WhatsApp, Telegram, or scheduled doubt sessions.
36. What is the course fee?
Fees vary by batch type; please contact us directly for current offers.
37. EMI or installment option available?
Yes, we offer flexible payment options with monthly installments.
38. Do you offer discounts for students or groups?
Yes, group discounts and early bird offers are available.
39. What are the batch timings?
We offer weekday and weekend batches in both morning and evening slots.
40. Is fast-track training available?
Yes, custom fast-track options are available for working professionals.
41. What makes your institute different from others?
We focus on real-time projects, personal mentorship, and guaranteed placement support.
42. Do you provide offline classroom training in Hyderabad?
Yes, we have physical classroom batches available in Hyderabad.
43. Can I switch from online to offline during the course?
Yes, we offer flexible mode switching depending on seat availability.
44. Will I get a course completion certificate?
Yes, a certificate will be provided after successful completion of the training.
45. Is internship provided?
We offer internship-like project experience and certification upon completion.
46. Do you offer support after the course ends?
Yes, post-course support is available for doubts, projects, and interviews.
47. Can I revisit topics if I feel weak?
Yes, you can attend repeat sessions or access recorded videos anytime.
48. Do you have a community or alumni group?
Yes, we have an active alumni group for networking and job updates.
49. Can I contact trainers directly for help?
Yes, trainer support is available during and after the course.
50. Is this course suitable for a complete beginner?
Yes, it’s designed for both freshers and professionals new to AWS or data engineering.